Produce Like a Nerd (1): Oh My God, this is a Command Line?…
The story started with a bet in 2006, in a time without iPhones or even tablets. I had just brought in a new Apple Video iPod and a couple of mates at work — as well as me with a band background — thought it would be great if you could use it to make music somehow. Couldn't one write a programme for the gadget that lets you display your own instrumental part and play a backing track simultaneously? That's impossible for sure…
Well, it would have been possible to program something, but all the effort on a rather exotic hardware and software platform just for a bet? But a video iPod could also — cunning idea😉 — play a video, that means, one that displays the notes, and the backing track would then simply be an audio track in that video.
Since I had already used various suitable open source tools at that time — such as lilypond for notation of band arrangements and ffmpeg for video editing — I could build a simple tool chain by hand. And so from a simple text file and practically without any manual intervention, a music video with audio track was created. Bach BWV 639.
Strike. I had won the bet back then (cf. figure 1). Of course. And it has fundamentally changed the way I produce arrangements ever since.

Well, enough said: what is this article about?
I shall demonstrate an approach how to use free open source tools upon text files with music and configuration data for a song to create the following automatically:
-
a PDF score of the whole song,
-
several PDF voice extracts,
-
a MIDI file with all voices (with additional preprocessing applied to achieve some humanisation),
-
audio mix files with several subsets of voices (specified by configuration), and
-
video files for several output targets visualizing the score notation pages and having the mixes as mutually selectable audio tracks as backing tracks.
And you can generate those files on an arbitrary platform — Windows, Linux, MacOS or others — as long as you can run the required open source tools on it.
Well, what's it all for? Very simple: I occasionally do live performances in different lineups: sometimes as a duo with my wife and sometimes as a trio with buddies. Then we can play those arrangement videos on a tablet on stage and select backing tracks containing only those voices not being played live. All this is fed into the mixer and will be played back in sync with the score displayed. And someone even automatically turns the pages…
But there is a catch — and probably many will stop reading now at the latest —: for a song you have to write a text file for the arrangement (in a standard notation of the score writer program Lilypond) and a configuration text file for the description of the instrument audio tracks, the audio effects and the video properties as well as the several tracks in the videos.
Via COMMAND LINE several open source programs are called that
do the essential work. But this tool chain is orchestrated
by a single program, the LilypondToBandVideoConverter
(abbreviated “ltbvc”). It controls
the processing steps: based on data given in a song-dependent
configuration file plus the lilypond fragment file for the
notes of the voices, it adds boilerplate lilypond code,
parametrizes the tool chain and calls the necessary programs
automatically. Additionally the audio generation can be
tweaked by defining MIDI humanization styles and command
chains (“sound styles”) for the audio
postprocessing.
And the process is completely unattended: once the required configuration and lilypond notation files are set up the process runs on its own. By that, it can be repeated at will and also selectively used when only some of the above target files need an update.
Open Source Programs Used
To get all that running, several command-line programs have to be installed, which are available for Windows, MacOS and Linux:
-
python3: an interpreter for a common script language (this is typically pre-installed on most operating systems),
-
lilypond: a text-based score writing program [Lilypond] for the score, the voice extracts, the raw MIDI file and for the pages used in the videos,
-
ffmpeg: a program for video generation and transformation [FFMpeg],
-
fluidsynth: a converter from MIDI to audio via soundfonts [Fluidsynth], and
-
sox: a program for audio effects [SoX].
For fluidsynth you will need a good soundfont. There are a lot of those in the internet, the most common is FluidR3_GM.sf2 [SFFluid].
On top of that there are no specific requirements on the program versions, because only their standard functions are used. Very often an existing version can be used without problems.
And finally one has to download and install the free open source program LilypondToBandVideoConverter from GitHub or PyPi [LTBVC] and now is ready to go.
At least if you are able to open a command-line window on your platform…
Processing Phases
The program has several processing phases named by the kind of result they produce:
-
extract: generates PDF notation files for single voices as extracts,
-
score: generates a single PDF file containing all voices as a score,
-
midi: generates a MIDI file containing all voices with specified instruments, pan positions and volumes (and some humanisation applied),
-
silentvideo: generates one or more silent videos containing the score pages for several output video file kinds (with configurable resolution and size),
-
rawaudio: generates unprocessed (intermediate) audio files for all the instrument voices from the MIDI tracks,
-
refinedaudio: applies configurable audio processing to the unprocessed audio files and generates (intermediate) refined audio files,
-
mix: generates final audio files with submixes of all instrument voices based on the refined audio files with a specified volume balance and some subsequent mastering audio processing (where the submix variants are configurable), and
-
finalvideo: generates a final video file with all submixes as selectable audio tracks and with a measure indication as subtitle
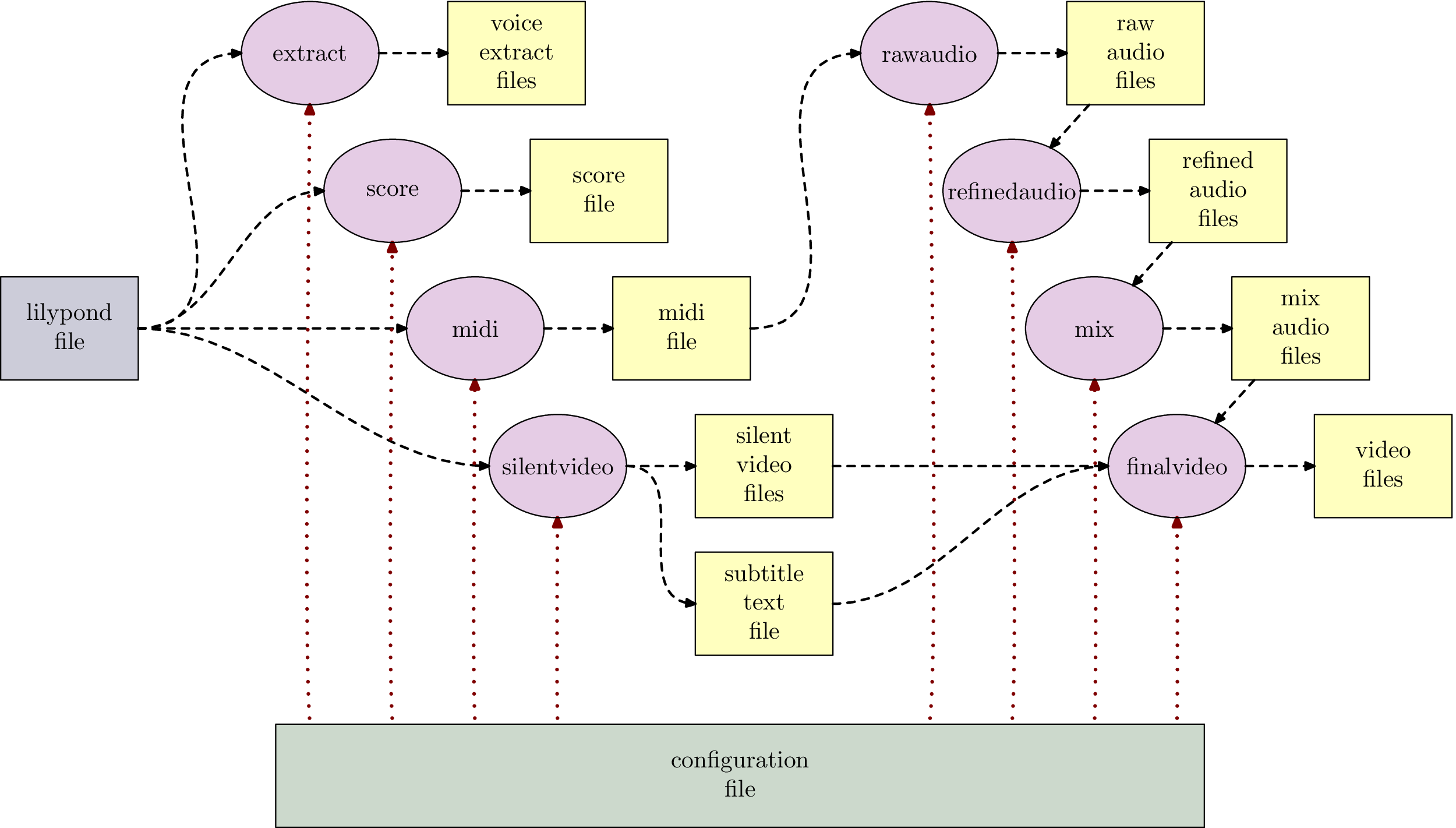
Figure 2 shows how the phases depend on each other. Files (in yellow) are generated by the phases (in magenta), the configuration file (in green) and the lilypond fragment file (in blue) are the only manual inputs into the processing chain.
Typically the phases are interdependent: a “raw audio file” can only be generated, when a “MIDI file” has been generated before.
It is also striking, that the whole processing chain has only two inputs: a lilypond file with the score data and the configuration file for overall or song-specific settings: voice names, MIDI instruments, styles of humanisation, video file kinds etc.
Once everything has been put into those files, the processing
steps can be executed in total or selectively. The command
is lilypondToBVC so, for example, as
lilypondToBVC score mySong-config.txt
The whole process does not consume a lot of time: complex arrangements of real songs with several instruments take about 20s on a current PC and much faster, of course, when only single phases are processed (for example, when the audio effect chain has changed, which has nothing to do with the score file).
File Format Overview
So, something with text files: why should this be relevant?
Anyone who has done music notation in the past knows that it is quite possible to set voice extracts or scores excellently by using text files. A notorious example for this was the SCORE program by Leland Smith [Score] with a complicated syntax, which nevertheless had even been used by publishers (for example, Schott), because you could produce great looking results far exceeding those of graphical programs.
The text oriented approach has the main disadvantage, that you cannot see immediately or even manipulate visually, how the score layout looks. But the compelling advantage of those textual score programs is, that you can, for example, recycle parts of your songs as macros and even parametrise them (like in a programming language!). This is especially helpful for pattern-based music — and most rock/pop songs fall in that category —. A comparably small effort then leads to reasonable results.
Lilypond is currently the most prominent representative of this program species of score writing systems. It is an open source program able to transform text files into score PDF and MIDI files via the command line.
A very simple lilypond file test.ly is for
example:
\version "2.22.0"
scale = \relative c' { f4 g a b | c d e f | }
\score { \scale }
There are a lot of words with a preceding backslash: those are commands in lilypond. You can, for example, select the lilypond version (“version”) or define the score (“score”). The curly braces are used for grouping, similar to programming languages. But it is important to note that you can also define your own commands in lilypond: “scale” is defined to be an ascending lydian-f-scale with quarter notes and it can be used at an arbitrary position in the file (with a leading backslash).
The command lilypond test.ly produces a PDF
file (figure 3a). Later on we shall not be using
lilypond directly, but instead rely on the
LilypondToBandVideoConverter which calls
lilypond behind the curtains.
 |
 |
|
| (a) | (b) |
You don't say: I now can write a simple scale with a lot of cryptical commands, great. Welcome in the 1980s…
Well, if you replace the line
\scale
by
\scale \transpose f c { \scale }
you get the original scale and another one transposed down by a fourth, a lydian c-scale (figure 3b). This is only scratching the surface here: it is somewhat a programming of music, but when you like that abstraction and can cope with that, it is very powerful.
Okay, we now have a broad idea on how to get notes into a text file and translate them into a PDF file, but how do we get audio and video from that?
For that you need a configuration file that contains information about the voices, the instruments and the audio effects. Such a configuration file contains key-value-pairs, for example, the command for video generation or a list of volumes for the several instruments.
Let's look at an example:
_initialTempo = 90
humanizedVoiceNameSet = "vocals"
voiceNameList = "vocals, guitar"
humanizedVoiceNameSet = humanizedVoiceNameSet ", drums"
measureToTempoMap = "{ 1 : " _initialTempo ", 20 : 67 }"
As you can easily see a configuration file has a simple structure; we shall cover the details in a moment.
A Case Study
Let us have a look at the approach via a demo example.
The demo song is a twelve-bar blues in e major with two verses and some intro and outro. Note that this song is just an example, its musical merit is limited.
In the following we shall work with two files:
-
a lilypond music file containing the music fragments used by the generator, and
-
a song-specific configuration file containing the settings for the song (like, for example, the title of the song or the voice names) plus some overall settings (like, for example, the path to programs).
Often the single configuration file is split into a general file (with overall settings) and a song-specific fragment file thus keeping global and song-specific stuff separate. But to keep it simple for the example, we only use a single configuration file and also rely a lot on default settings. The same goes with the music fragment file: you could also split this if needed.
In the following we explain the lilypond fragment file and the configuration file in a piecewise manner according to the requirements of the different processing phases presented in sections, for example, the parts of the configuration file needed for setting up a score file.
But first we start with the notes in the music fragment file. This has to be complete, before we can generate anything meaningful.
The Lilypond File
The lilypond fragment file starts with the inclusion of the note name language file (using, for example, “ef” for e♭ or “cs” for c♯); additionally the first musical definition is the key and time designation of the song: it is in e major and uses common time.
\include "english.ly"
keyAndTime = { \key e \major \time 4/4 }
The chords are those of a plain blues with a very simple intro and outro. Note that the chords differ for extract and other notation renderings: for the extract and score we use a volta repeat for the verses, hence in that case all verse lyrics are stacked vertically and we only have one pass of the verse.
All chords are generic: there is no distinction by instrument.
chordsIntro = \chordmode { b1*2 | }
chordsOutro = \chordmode { e1*2 | b2 a2 | e1 }
chordsVerse = \chordmode { e1*4 | a1*2 e1*2 | b1 a1 e1*2 }
allChords = {
\chordsIntro \repeat unfold 2 { \chordsVerse }
\chordsOutro
}
chordsExtract = { \chordsIntro \chordsVerse \chordsOutro }
chordsScore = { \chordsExtract }
b1*2 means that it is a b-major chord with a
duration of a whole note (1/1) and this goes for two
measures (“*2”). Analogously there is an
a2; this is an a-major chord with duration of a
half note (1/2). The chords are repeated twice
(repeat fold 2) and preceeded by the intro and
followed by the outro.
The vocals are simple with a pickup measure. Because we want
to keep the structure consistent across the voices we have to
use two alternate endings for the vocalsExtract
and vocalsScore.
vocTransition = \relative c' { r4 b'8 as a g e d | }
vocVersePrefix = \relative c' {
e2 r | r8 e e d e d b a |
b2 r | r4 e8 d e g a g | a8 g4. r2 | r4 a8 g a e e d |
e2 r | r1 | b'4. a2 g8 | a4. g4 d8 d e | e2 r |
}
vocIntro = { r1 \vocTransition }
vocVerse = { \vocVersePrefix \vocTransition }
vocals = { \vocIntro \vocVerse \vocVersePrefix R1*5 }
vocalsExtract = {
\vocIntro
\repeat volta 2 { \vocVersePrefix }
\alternative {
{ \vocTransition }{ R1 }
}
R1*4
}
vocalsScore = { \vocalsExtract }
If you have a closer look at vocalsExtract,
you'll find that the first measure is a rest
(“r1”, rest for 1/1), followed by a
vocTransition and two times the verse
consisting of vocPrefix and
vocTransition; the outro is just four measures
of silence (“R1*4”).
The demo song also has lyrics, but they don't deserve a Nobel Prize. Nevertheless note the lilypond separation for the syllables and the stanza marks. For the video notation the lyrics are serialized. Because of the pickup measure, the lyrics have to be juggled around.
vocalsLyricsBPrefix = \lyricmode {
\set stanza = #"2. " Don't you know I'll go for }
vocalsLyricsBSuffix = \lyricmode {
good, be- cause you've ne- ver un- der- stood,
that I'm bound to leave this quar- ter,
walk a- long to no- ones home:
go down to no- where in the end. }
vocalsLyricsA = \lyricmode {
\set stanza = #"1. "
Fee- ling lone- ly now I'm gone,
it seems so hard I'll stay a- lone,
but that way I have to go now,
down the road to no- where town:
go down to no- where in the end.
\vocalsLyricsBPrefix }
vocalsLyricsB = \lyricmode {
_ _ _ _ _ _ \vocalsLyricsBSuffix }
vocalsLyrics = { \vocalsLyricsA \vocalsLyricsBSuffix }
vocalsLyricsVideo = { \vocalsLyrics }
The bass simply hammers out eighth notes. As before there is an extract and a score version with volta repeats and an unfolded version for the rest (for MIDI and the videos).
bsTonPhrase = \relative c, { \repeat unfold 7 { e,8 } fs8 }
bsSubDPhrase = \relative c, { \repeat unfold 7 { a8 } gs8 }
bsDomPhrase = \relative c, { \repeat unfold 7 { b8 } cs8 }
bsDoubleTonPhrase = { \repeat percent 2 { \bsTonPhrase } }
bsOutroPhrase = \relative c, { b8 b b b a a b a | e1 | }
bsIntro = { \repeat percent 2 { \bsDomPhrase } }
bsOutro = { \bsDoubleTonPhrase \bsOutroPhrase }
bsVersePrefix = {
\repeat percent 4 { \bsTonPhrase } \bsSubDPhrase \bsSubDPhrase
\bsDoubleTonPhrase \bsDomPhrase \bsSubDPhrase \bsTonPhrase
}
bsVerse = { \bsVersePrefix \bsTonPhrase }
bass = { \bsIntro \bsVerse \bsVerse \bsOutro }
bassExtract = {
\bsIntro
\repeat volta 2 { \bsVersePrefix }
\alternative {
{\bsTonPhrase} {\bsTonPhrase}
}
\bsOutro
}
bassScore = { \bassExtract }
The guitar plays arpeggios. As can be seen here, very often the lilypond macro structure is similar for different voices.
gtrTonPhrase = \relative c { e,8 b' fs' b, b' fs b, fs }
gtrSubDPhrase = \relative c { a8 e' b' e, e' b e, b }
gtrDomPhrase = \relative c { b8 fs' cs' fs, fs' cs fs, cs }
gtrDoubleTonPhrase = { \repeat percent 2 { \gtrTonPhrase } }
gtrOutroPhrase = \relative c { b4 fs' a, e | <e b'>1 | }
gtrIntro = { \repeat percent 2 { \gtrDomPhrase } }
gtrOutro = { \gtrDoubleTonPhrase | \gtrOutroPhrase }
gtrVersePrefix = {
\repeat percent 4 { \gtrTonPhrase }
\gtrSubDPhrase \gtrSubDPhrase \gtrDoubleTonPhrase
\gtrDomPhrase \gtrSubDPhrase \gtrTonPhrase
}
gtrVerse = { \gtrVersePrefix \gtrTonPhrase }
guitar = { \gtrIntro \gtrVerse \gtrVerse \gtrOutro }
guitarExtract = {
\gtrIntro
\repeat volta 2 { \gtrVersePrefix }
\alternative {
{\gtrTonPhrase} {\gtrTonPhrase}
}
\gtrOutro
}
guitarScore = { \guitarExtract }
Finally the drums do some monotonic blues accompaniment. We
have to use the myDrums name here, because
drums is a predefined name in lilypond. There
is no preprocessing of the lilypond fragment file that could
fix this: the fragment is just included into some boilerplate
code, hence it must be conformant to the lilypond syntax.
drmPhrase = \drummode { <bd hhc>8 hhc <sn hhc> hhc }
drmOstinato = { \repeat unfold 2 { \drmPhrase } }
drmFill = \drummode {
toml toml tomfl tomfl }
drmIntro = { \drmOstinato \drmFill }
drmOutro = \drummode {
\repeat percent 6 { \drmPhrase } | <sn cymc>1 | }
drmVersePrefix = {
\repeat percent 3 { \drmOstinato } \drmFill
\repeat percent 2 { \drmOstinato \drmFill }
\repeat percent 3 { \drmOstinato }
}
drmVerse = { \drmVersePrefix \drmFill }
myDrums = { \drmIntro \drmVerse \drmVerse \drmOutro }
myDrumsExtract = {
\repeat volta 2 {\drmVersePrefix}
\alternative {
{\drmFill} {\drmFill}
}
\drmOutro }
myDrumsScore = { \myDrumsExtract }
So we are done with the lilypond fragment file. What we have defined are
the song key and time,
the chords,
the vocal lyrics, and
voices for vocals, bass, guitar and drums.
All those definitions take care that the notations shall differ in our case for extracts/score and other notation renderings.
Unfortunately this is not a complete lilypond file, but only
a fragment containing the net information. Some additional
boilerplate code would have to be added. You could do this
manually and then run lilypond directly or use the
ltbvc instead.
Because the LilypondToBandVideoConverter can handle that, we use it. But then we also need a configuration file…
Example Configuration File for the LilypondToBandVideoConverter
Our configuration file contains global settings as well as song-specific settings.
As a convention we prefix auxiliary variable with an underscore to distinguish them from the “real” configuration variables.
If the programs are in special locations one has to define
the specific paths for them. When they are however reachable
by the system's program path (which is normally the
case) nothing has to be done. But this is not completely
true, because, for example,
midiToWavRenderingCommandLine needs special
handling, a command we shall later use for audio generation:
it command line has to be specified because for fluidsyth as
WAV renderer we have to specify the soundfont location (which
ltbvc is unable to deduce).
Other global settings would define paths for files or directories, but for most settings we rely on the defaults. But we want the temporary lilypond file to go to “temp” (and have some parts in the name for phase and voice name), the generated PDF and MIDI files to go to subdirectory “generated” of the current directory and audio into “mediafiles”). Note that those directories have to be created manually before running the program, since it checks for their existence before doing something.
tempLilypondFilePath = "./temp/temp_${phase}_${voiceName}.ly"
targetDirectoryPath = "./generated"
tempAudioDirectoryPath = "./mediafiles"
The song is characterized by its tile and the file name prefix used for the generated files.
title = "Wonderful Song" fileNamePrefix = "wonderful_song"
The main information about a song is given in the table of voices with the voice names where later on MIDI data, reverb levels and the sound variants will be added.
voiceNameList = "vocals, bass, guitar, drums"
The overall tempo is 90bpm throughout the song. You could add some tempo change in this list, but this in not necessary here.
measureToTempoMap = "{ 1 : 90 }"
Settings for Voice Extracts and Score
For the voice extracts and the score there is a small note about the arranger.
composerText = "arranged by Fred, 2019"
We also have lyrics. Here we must define, what voices use
them and whether there are parallel lyrics because of
repeats. In our case there are two lines of lyrics in the
“vocals” extract (e2) and in the
score (s2), one (serialized) line in the video
(v).
voiceNameToLyricsMap = "{ vocals : e2/s2/v }"
Also the default notation settings are fine: they ensure that drums use the drum staff, that the clefs for bass and guitar have the voices transposed by an octave up resp. down and that drums have no clef at all. Chords shall be shown for all extracts of melodic instruments and on the top voice “vocals” in the score and video. If this were not okay, we'd have to adapt special variables.
| (a) |  |
(b) |  |
|
| (c) |  |
(d) |  |
Figures 4a-d show the resulting voice extracts after the command
lilypondToBVC --phases extract wonderful_song-config.txt
For the score the command is
lilypondToBVC --phases score wonderful_song-config.txt
Figure 5 shows the resulting score. It is quite easy to see the analogy in the note representations between the PDF rendering and the lilypond representation from the previous section.

Settings for the MIDI File
The MIDI file can be generated from the same lilypond file; already lilypond can do that, so this is not much of a surprise.
But the MIDI file generated by lilypond sounds a bit static,
hence there are several settings in the ltbvcto
improve that.
First of all for each of the voices their specific settings
are defined by several list variables corresponding to the
list voiceNameList. This means that, for
example, for third entry in voiceNameList (here
“guitar”) the third entry in
midiVolumeList (here 70) defines its MIDI
volume. So it is helpful to visually align the list entries
as follows:
voiceNameList = "vocals, bass, guitar, drums" midiInstrumentList = " 18, 35, 26, 13" midiVolumeList = " 100, 120, 70, 110" panPositionList = " C, 0.5L, 0.6R, 0.1L" reverbLevelList = " 0.3, 0.0, 0.0, 0.0"
Let's have a look at one entry: the bass will be played with general MIDI instrument 35 (this is by definition a “fretless bass”) with a volume of 70 (of at most 127 units) located at 50% left in the stereo spectrum and without any reverb (at least in the MIDI file; this will later be corrected during audio refinement).
On top of that a “MIDI humanisation” can be applied for the MIDI file and this will, of course, also apply to the generated sound files. This kind of humanisation typically depends on the song.
Humanization is defined as patterns and applied by adding random variations in timing and velocity to the notes in a voice. This is not completely random, but depends on voice, position within measure and on the style of the song.
Relative positions in a measure have assigned a change in note velocity and a change in timing (ahead or behind). The changes are random and relative to a reference value. For the velocity the reference value is a factor near 1.0 for multiplying the original velocity of some note. For the timing the reference value is the original time of the note on event. Those are modified by a position-independent variation of the velocity (“SLACK”) and a position-dependent variation in time. Both variations are — as mentioned — random with a distribution favouring small values.
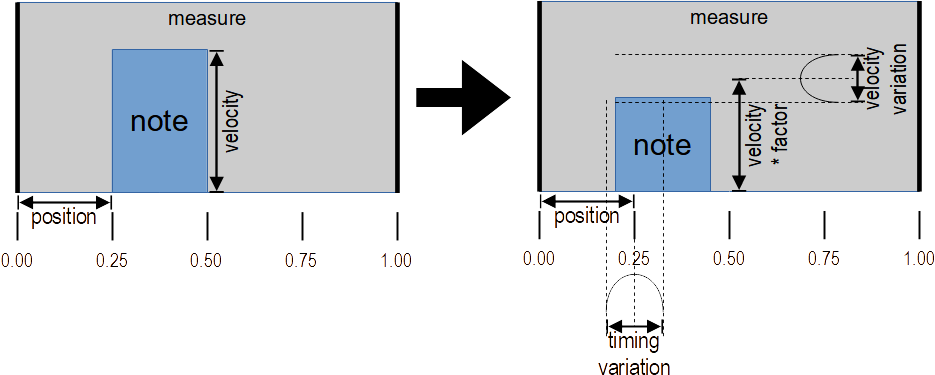
Figure 6 shows the example humanization of a single note in a measure by the above algorithm: its velocity is multiplied by a position independent factor and the a random slack is added with a position-independent range. The starting time is varied by a position-dependent variation range. The parabola curves in the diagram visualize the emphasis on smaller variation values.
The song just has a single humanisation pattern: a rock groove with precise hits on 2 and 4 (hence at 25% and 75% of a measure) and small timing variations for other positions in a measure. Those variations are very subtle and are bounded by 0.3 raster units. Because the raster is given as a 32nd note, the variation is at most 32nd ×0,3. For the velocity there is a hard accent on two and a lighter accent on four, the other positions are weaker.
There are no individual variation factors per instrument in our example. But this could be set, for example, when the drums should have a more precise timing than the bass. In the example all humanized instruments have similar timing and velocity variations.
All available humanization styles in the configuration file
must have a fixed prefix humanizationStyle in
their names to be elegible:
humanizationStyleRockHard =
"{
" 0.00: 0.95/A0.1, 0.25: 1.15/0,"
" 0.50: 0.98/0.3, 0.75: 1.1/0,"
" OTHER: 0.85/0.25,"
" SLACK:0.1, RASTER: 0.03125 }"
The song itself defines the styles to be applied as a style map from measure number to style starting here; the above style will be used starting at measure 1 and throughout the song for all voices except the vocals:
humanizedVoiceNameSet = "bass, guitar, drums"
measureToHumanizationStyleNameMap =
"{ 1 : humanizationStyleRockHard }"
There also is a two measure count-in (in case you want to play along 😉):
countInMeasureCount = 2
With all the information the MIDI file can be generated via
lilypondToBVC --phases midi wonderful_song-config.txt
Figure 7 shows the MIDI file from lilypond directly and the one after humanisation. The accentuation of beats two and four by the humanisation is quite clearly recognisable.
To make the comparison independent from the reader's local MIDI player both MIDI files were rendered into audio with the same soundfont.
| (a) | (b) |
Okay, this sounds a little better, but still not great. We have to improve that by the audio postprocessing later…
Settings for the Video Generation (without Audio)
We already have a score and the voice extracts as PDF files and a MIDI file. If we want to have a video file with all the voices as audio tracks, we first of all need a video. The basic idea is simple: all the repeats in the song are expanded, then the notes are “photographed” pagewise and in the video each such page is shown exactly for the duration of that section. Additionally — and this would, of course, be unnecessary for an orchestra musician 😉 — the current measure number is shown as a subtitle in order not to get lost during playback.
As always the configuration defines the voices to occur in the videos. For a “karaoke video” only the vocal voices will be used, but you also could have the complete score or something in between.
There are two things you'll have to configure_
-
one or more video targets, which define the resolution, orientiation, margins etc. of the video and
-
one or more video file kinds, which define the set of voices in the videos and the file naming convention.
You could generate a video for a tablet in portrait format (as a video target), another one for a smartphone in landscape format (as a video target), and the first shows the score (defined by a video file kind) and the second only shows the vocals (also defined by a video file kind).
For the example we take a single video target and video file kind. Do not be irritated by the target name “tablet”, it just is a video sized 768x1024 with a resolution of 132ppi. It should work on any platform (that can handle the format 😉).
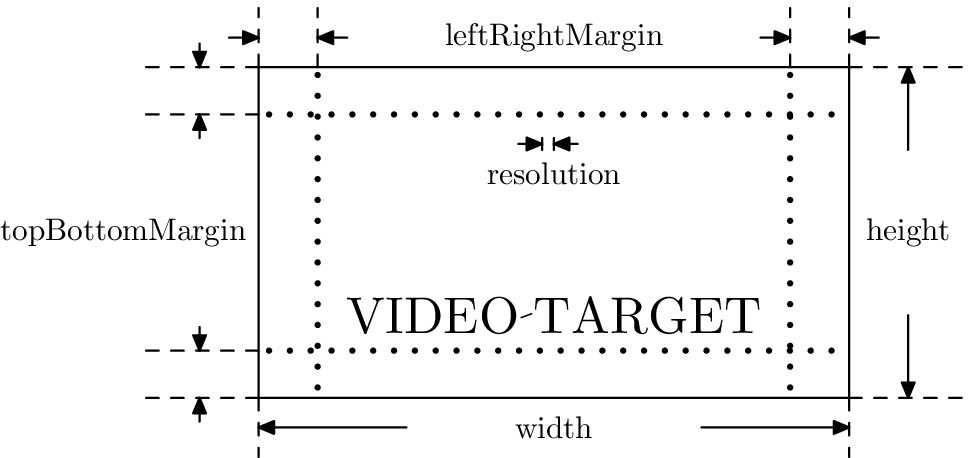
videoTargetMap = "{
"tablet: {
" height: 1024,"
" width: 768,"
" topBottomMargin: 5,"
" leftRightMargin: 10,"
" scalingFactor: 4,"
" frameRate: 10.0,"
" mediaType: 'Music Video',"
" systemSize: 25,"
" subtitleColor: 2281766911,"
" subtitleFontSize: 20,"
" subtitlesAreHardcoded: true } }"
Figure 8 shows what kind of dimensions are set in a video target; each of them is specified either in pixels or pixels per inch.
The video file kind uses this video target format and defines on top of it, that vocals and guitar are shown in the video and that the files are stored as “./mediafiles/SONGNAME-tblt-vg.mp4”.
videoFileKindMap = "{
"tabletVocGtr: {
" fileNameSuffix: '-tblt-vg',"
" directoryPath: './mediaFiles' ,"
" voiceNameList: 'vocals, guitar' } }"
Note that both lists may contain several entries, but this is an advanced usage of the system…
If you do not define a video target, the default (also named “tablet” incidentally) is a video with 640x480 pixels and a resolution of 64ppi. The default video file kind uses “tablet” and just shows the vocals.
The command
lilypondToBVC --phases silentvideo wonderful_song-config.txt
generates two files: a silent video and a subtitle file (figure 9).
Interim Conclusion
We have already sucked out several things from the lilypond file:
-
voice extracts and score (as PDF files),
-
a (somewhat humanised) MIDI file, and
-
a silent notation video with the measure numbers as subtitles.
As you can see in figure 10, we are done with the lilypond file, the rest will be produced from the intermediate results. For example, the notation video needs additional audio tracks (ideally with different voices).
And it does not get better: also the generation of the audio tracks and the integration into the final video will be done via the command line. But all will be set up by the configuration file.
Settings for the Audio Generation
The MIDI file can be transformed into audio files with the
single voices. Unfortunately there are not a lot of programs
that can do this, are reasonably flexible and also deliver a
good audio quality. A quite common program for that is
fluidsynth, which uses the so-called soundfonts
and is available for the typical platforms. Soundfonts
contain sampled instruments (together with envelope and
modulation definitions etc.). You can find really usable
ones in the internet and especially one that cover all
general MIDI instruments (for example, the FluidR3_GM.sf2
from the introduction).
The ltbvc does not care about the
transformation programme and it does not have to work with
soundfonts. One could easily use another one as long as it
expects the names of a MIDI file and audio file on its
command line.
Nevertheless the pattern for the command line must be
specified in the configuration file via the variable
midiToWavRenderingCommand. Even if you use
“fluidsynth” itself, it is mandatory, because it
contains the path of the soundfont and there is no default
for it. Moreover there are placeholders for the MIDI input
file and the WAV target file. In our example we assume that
fluidsynth is the MIDI to WAV converter.
_soundFonts = "/usr/local/midi/soundfonts/FluidR3_GM.SF2"
midiToWavRenderingCommandLine =
"fluidsynth -n -i -g 1 -R 0"
" -F ${outfile} " _soundFonts " ${infile}"
The command
lilypondToBVC --phases rawaudio wonderful_song-config.txt
generates four audio files for drums, guitar, vocals and bass. Those really are “raw” instrument tracks, because even a reverb in the MIDI instrument is deactivated for the generation.
| (a) | (b) | |||
| (c) | (d) |
Settings for the Audio Refinement
Okay, those raw audio tracks need some beefing up. Again we need a program that can apply audio effects on those tracks.
SoX is such a command line program where chains of effects are applied to audio input. For example, the command
sox input.wav output.wav highpass 80 2q reverb 50
applies a double-pole high pass filter at 80Hz with a
bandwidth of 2Q followed by a medium reverb on file
input.wav and stores the result in file
output.wav.
sox has a lot of those filters and all those can be used for sound shaping. In this document we cannot go into details, but a thorough information can be found in the sox documentation [SoX].
Of course, it is also possible to use another command-line
audio processor by setting the variable
audioProcessor appropriately and adapting the
refinement commands for the voices for the tool used. But
this is an expert solution beyond the scope of this
documentation; hence you are on your own…
Each audio voice is transformed depending on voice-specific settings in the configuration file. The input file comes from the previous “rawaudio” phase (for example “bass.wav”) and the output file name for the “refinedaudio” phase is also well-defined (for example as “bass-processed.wav”).
We only have to specify the sox effects for the transformation itself. This is done via the so-called sound style variables with their names constructed from the prefix “soundStyle” followed by the voice name with initial caps (for example “Bass”) and by the style variant — a single word — capitalized as suffix (“Hard”). When following this convention, a hard bass has a sound style name “soundStyleBassHard”.
It is possible to define a library of effect chains in central files, but it is also typical to define song-specific styles in its configuration file. This is exactly what we are going to do: we are defining four styles “Bass-Crunch”, “Drums-Grit”, “Guitar-Crunch” and “Vocals-Simple”.
The bass will be companded with an attack of 30ms, 100ms release and a 4:1 ratio with a threshold of -20dB, followed by a second order highpass at 60Hz, a second order lowpass at 800Hz and an equalizer at 120Hz with +3dB (all filters with a bandwidth of one octave) finally followed by a reverb with 60% level and several other settings.
soundStyleBassCrunch =
" compand 0.03,0.1 6:-20,0,-15"
" highpass -2 60 1o lowpass -2 800 1o equalizer 120 1o +3"
" reverb 60 100 20 100 10"
The other styles look similar; details can be found in the SoX documentation.
soundStyleDrumsGrit = "overdrive 4 0 reverb 25 50 60 100 40"
soundStyleGuitarCrunch =
" compand 0.01,0.1 6:-10,0,-7.5 -6"
" overdrive 30 0 gain -10"
" highpass -2 300 0.5o lowpass -1 1200"
" reverb 40 50 50 100 30"
soundStyleVocalsSimple = " overdrive 5 20"
And the mapping between voices and sound styles is done
similarly to the MIDI definitions above: by the columns in
voiceNameList and
soundVariantList. The latter contains only the
style variants as follows:
voiceNameList = "vocals, bass, guitar, drums" ... soundVariantList = "SIMPLE, CRUNCH, CRUNCH, GRIT"
If you executed the command
lilypondToBVC --phases refinedaudio wonderful_song-config.txt
four refined instrument audio tracks are generated for drums, guitar, vocals and bass, where the effect chains are applied to the raw audio files. Figure 12 shows raw and refined audio files in comparison.
| (a) | (b) | |||
| (c) | (d) |
Mixing into Audiotracks for the Notation Video
In principle, those refined audio tracks could be used in an appropriate multitrack context, for example, as stems in an audio player. It is then also possible to select those tracks that are required at the moment and mute all the others.
But instead of using a special software or hardware, we want to use a standard program for video playback on an arbitrary device. Unfortunately you cannot activate multiple tracks in video players, but only a single one (for example to select one of multiple audio language tracks in a movie).
The workaround is to produce a submix for each relevant combination of instrument audio tracks and store that as an audio track in the video. For five instruments this would lead to 32 submixes covering any possible combination. But this is often not necessary, because it requires a lot of storage space in the target file; typically one would only select those ones required.
To define this selection of the tracks each one is characterized by name, set of voices and the corresponding volumes as follows:
_voiceNameToAudioLevelMap =
"{ vocals : -4, bass : 0, guitar : -6, drums : -2 }"
audioTrackList = "{
"all : {
" audioGroupList : bass/vocals/guitar/drums,"
" languageCode: deu,"
" voiceNameToAudioLevelMap : " _voiceNameToAudioLevelMap "},"
"novoice : {
" audioGroupList : bass/guitar/drums,"
" languageCode: eng,"
" voiceNameToAudioLevelMap : " _voiceNameToAudioLevelMap "},"
"}"
This means the video has two tracks: one with all voices and
another one with all voices except the vocals. The volumes
of the voices are given in the table
voiceNameToAudioLevelMap with decibel entries.
Both tracks habe the same relative voice volumes; this could
be varied.
Somewhat surprising is that you have to specify a “languageCode”: this is just the code for the language specifying what identification is used for a track within the final video. Many video players are not able to display the audio track name or its description, hence we revert to the language instead (for example “English” instead of “novoice”). It is just a workaround and completely arbitrary; you just have to remember that the karaoke track without vocals is “English”.
The command
lilypondToBVC --phases mix wonderful_song-config.txt
generates two audio tracks with the corresponding submixes.
| (a) | (b) |
Combination of the Audio Tracks with the Notation Video
Now for the last step: we combine the silent video with the audio tracks.
Fortunately we have defined everything we need for the
configuration file in the previous sections. Relevant are
the entries for videoFileKindMap and
audioTrackList. If
videoFileKindMap contains multiple entries,
several videos are generated, which contain all tracks
of the audioTrackList.
The command
lilypondToBVC --phases finalvideo wonderful_song-config.txt
produces a video file, which can be viewed in figure 14.
Summary
This has been a tough ride so far.
We have tediously (but nevertheless!) produced the following: from a text file for an arrangement and a configuration file using some open source programmes and the coordination program LilypondToBandVideoConverter we automatically (!) get
-
PDF voice extracts,
-
a PDF score,
-
a MIDI file,
-
audio stems,
-
several submixes of those as audio file and finally
-
a notation video with those submixes, where you can select the required one for playback.
The presented approach is quite elaborated and you can achieve reasonable results with it. However, you have to get into a mode of operation where you do corrections in text files and have to run some translator programme to finally see whether the corrections are okay or not.
Objection and Consolation
Well, buddy, this sounds funny and quirky. In the 70s my granny handed over punch cards to the operator and five hours later she saw in a paper listing that her programme did not work as she thought. Edit-compile-run, that's what it used to be called.
But that is not the way how you work today: nowadays everything is done in real-time!!Slowly, slowly catchy monkey! In part 2 we shall see, how this approach can be combined with a DAW and how you can do all this more interactively and possibly also more efficently…