PSINOWEB preprocessor
(literate programming for EPOC)
Overview
PSINOWEB processes a text or PSION word file containing a literate program written in PSINOWEB and transforms it to text files.
A literate program combines documentation (called documentation chunks) and code sequences (called code chunks). Code chunks represent the contents of some target file which is always a text file. Its format is arbitrary: it doesn't have to be a program file.
The documentation chunks may have any contents and layout. They must not contain the special sequence "<<" at the beginning of a line and ">>=" at its end (as those strings characterize the start of a code chunk). Documentation chunks may even contain objects from other programs like tables or diagrams.
Code chunks start with the special sequence "<<" at the beginning of a line and ">>=" at its end. They may be presented in arbitrary order in the literate program source. This does not matter as they must have unique names and reference each other by name. So one code chunk may "include" the contents of some other chunks.
A code chunk ends at either the beginning of another code chunk, at the end of file or at the character '@' on a line by itself.
E.g. the text
<<a chunk>>=
IF a=b
PRINT b
<<chunk a>>
<<chunk b>>
ENDIF
@
defines a chunk named "a chunk" with some expansion text and embedded chunks "chunk a" and "chunk b". Note that there is some real OPL code in this chunk and that "chunk a" and "chunk b" (hopefully) will expand to other OPL code.
If there are multiple definitions for a code chunk, the expansions are concatenated in the order of presentation. This is for example useful when variable definitions are widely distributed in the document but have to go to a specific location (e.g. the main routine).
All the code chunks should form a directed acyclic graph i.e. no chunk may contain itself in its expansion. This is checked by PSINOWEB and the program is terminated otherwise.
Normally one specific code chunk is the one representing the whole output and has to be the root of the graph. The default name for this chunk in PSINOWEB is "*". But any chunk can be taken as root for expansion. A PSINOWEB file may contain roots to many files even of different type as long as text format output is acceptable.
In a single run PSINOWEB normally processes one input file and expands one chunk from it into a target file. For convenience the user specifies the mapping (from input file via chunk to target file) in a so-called project file which may contain many such entries. At the beginning of the program the user selects the project file and either a specific or all entries in this file.
Experts in literate programming will note that this preprocessor does what is normally called "tangling" in l.p. parlour, hence a more appropriate name for this program would have been PSINOTANGLE. I have decided not to chose this name for two reasons: first there is no separate PSINOWEAVE since it's the original word file which should have a nice layout by itself and secondly when putting a program in the extras bar a name longer than eight characters does really not display well.
Format of input file
An input file can be a PSION-word file or a text file. PSINOWEB automatically detects the format of an input file.
The input is scanned for code chunks which are stored together with their expansions in some internal tables. Arbitrary chunks can be expanded to text target files. This is specified in detail by a project file (see below).
To be honest inputting a word file takes about three times longer than an equivalent text file. But it also has advantages to use a word file:
-
Documentation chunks and code chunks can be specially formatted. As the indentation of material in code chunks is preserved you should not indent code chunks unless necessary. Nevertheless one can indent the chunk headers and the code chunks in the word file by using appropriate document styles (see the enclosed OPW files for examples).
-
Pictures and other objects can be embedded in the file without interfering with the PSINOWEB processing.
-
Some characters in the word file are simply ignored by PSINOWEB. You can break code lines by inserting a line break (Shift-Enter). This is not possible in a text file.
If you want to combine the formatting capabilities of a word file with the speed of processing a text file you can simply export a text file from the word file. Now the project file must reference the text file as an input instead of the word file.
Format of target file
Each target file is a text file and contains the expansion of a specified root chunk. If the root chunk contains application of other chunks, those chunks are themselves expanded in place and so on.
Target files can be OPL program texts, configuration files and so on.
PSINOWEB preserves the relative indentation of material in a chunk. So when text 'ENDIF' in a definition of 'chunk x' is indented by four columns, 'chunk x' is indented two columns in a definition of 'chunk y', then 'ENDIF' is indented by six columns relatively to 'chunk y'.
Nevertheless the output of PSINOWEB is not intended for human consumption unless you very carefully insert white space in your code chunks. This is o.k.: the original file is the one to read and edit, not the generated file.
Format of project file
The project file consists of lines with a simple format. Each line specifies an input file (consisting of chunks), a root chunk and a target file where the expansion of the root chunk should go to. Those parts are separated by tabulators, hence the line
test\PSINOWEB.opw-->ROOT-->txt\PSINOWEB.txt
(where "-->" denotes a tabulator) specifies "test\PSINOWEB.opw" as the input file, "ROOT" as the root chunk to expand and "txt\PSINOWEB.txt" as the target file.
All file references are relative to the location of the project file. If the project file with the above line is "C:\Documents\projects.prj" then the entry says: convert file "C:\Documents\test\PSINOWEB.opw" to "C:\Documents\txt\PSINOWEB.txt" by expanding the chunk "ROOT". You may also specify absolut paths, but relative paths are often more flexible.
By the way: It is practical to keep lines with identical input files adjacent in the project file. PSINOWEB can be told to process all entries in the project file and will not reread an input file if it is already in memory.
Example of how to use PSINOWEB
Now for an example let's assume we have a literate OPL program written in PSION word. The file is called "primes.opw" and the chunk in it containing the OPL program skeleton is called "*". We cannot produce an OPL program from it directly (as PSINOWEB can put out text files only), but we can produce a text file with the OPL program. Let's call this file "primes.tpl".
To tell PSINOWEB this step a project file is needed. It must contain the line
primes.opw-->*-->primes.tpl
as an entry (where '-->' denotes a tab character). This project file can either be a text or a PSION-word file. Let's call this file "projects.prj".
Now we are set for PSINOWEB. A first dialog box comes up, where we specify the project file.
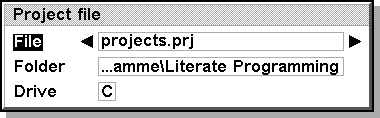
After this dialog has been done, a second dialog asks which of the project file entries has to be processed.
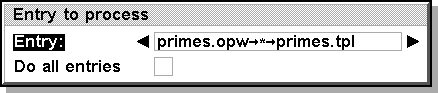
We select the line specified above and finish the dialog.
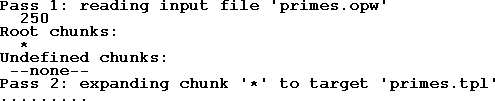
PSINOWEB reads "primes.opw" in a first pass and stores all chunk definitions into internal tables. After the first pass all chunks are reported which are roots in the chunk graph and also those chunks are reported which are applied somewhere but have no definition. Root chunks are no problem, but applied chunks without a definition always are. Finally the root chunk given in the project file entry (here "*") is expanded into the target file "primes.tpl".
To process "primes.tpl" further the OPL editor must be opened and the text file can be imported, compiled and tested. If only minor stuff is wrong, one should directly patch the OPL file instead of going through the generation cycle often (of course, the corrections should be done in parallel to the word file). When bigger problems occur (like totally misplaced or missing chunks) you will have to correct the original file and repeat the generation.
This sounds like a lot of hassle for a simple generation but note that you can automate a lot by using a tool like MACRO5. Also PSINOWEB stores the previous dialog settings; hence normally you just have to start this program and press "Enter" twice to start the process.
For your convenience the above example is already contained in the distribution. "primes.opw" is an OPL program to calculate the first thousand primes and print them and is an adaption of the standard example for literate programming by Donald E. Knuth.
Difference to conventional literate programming
Normally literate programming systems take the source file and process it in two ways: tangling expands chunks into target files (like PSINOWEB does) and weaving formats the source file specifically for human consumption. For example the classical WEB system tangles sources into PASCAL files and weaves sources into TeX files for printout.
In PSINOWEB there is no explicit weaving. The reason is that all formatting can be done in a word source file. This is not totally true as e.g. the generation of cross reference indices is something which can be done in a weaving step but is not automated in PSION-word. But for many purposes the limited approach taken by PSINOWEB is acceptable.
References
If you want to know more about literate programming, you can check the central literate-programming site www.literateprogramming.com or join the newsgroup comp.programming.literate.
PSINOWEB was inspired by Norman Ramsey's NOWEB system which is a highly useful system for doing literate programming on arbitrary platforms. Thanks to him for allowing me to use the term NOWEB in connection with PSI-...
Download
So here is the whole PSINOWEB-Distribution in zipped makesis-format.